









�S��AI�΄Տ��ƶˏV���³����O��߅�����˂�AI�����v�Ć�һ��֪�����s��ģ�B���������׃��@һ�M���������������ǰ��δ�е�Ҫ���������Ǻ��ε��������������nj�Ӌ��Ч�ʡ���Ч�����wϵ�y�����ĽK�O���ڴ˱����£�����Ӌ��ɞ��Ȼ�x��NPU���錣��AI���Ƶ�Ӌ���Ԫ������ĵ�λ�����@��
���գ����\�Ƽ�Arm China��ʽ�l��������һ��NPU IP�����ס�X3��ԓ�aƷ����һ�κ��εĵ������������ǏĵӼܘ��Ϟ�˂ȴ�ģ���������Ƶĸ���֮������ּ���cArm CPU��GPU�fͬ������һ��������Ч���`��Į�������������ֱָ��ǰ�˂�AI�ڲ����ģ�͕r���R����������������Ч�ȶ���ʹ�c��

һ���ܘ�������DSP+DSA�p����赣��Q�ٴ�ģ����Ч
�����ס�X3�ĺ���ͻ����������õ�����DSP+DSA�ܘ����@һ�����ģ���OӋ�ļܘ������F�ˏĶ��cӋ�㵽���cӋ����P�I��Խ������sģ���ṩ�˸��ߵľ��Ⱥ̈́ӑB������
�����ס�X3����w����ָ�����˲�Ŀ���������棬��Cluster���ṩ���_8-80 FP8 TFLOPS���`���������á��������棬��Core�������_256GB/s����Ч�������Ƽs��ģ���\�еġ��ȴ扦��ƿ�i�����⣬�����ס�X3֧��W4A8/W4A16�ȶ˂ȴ�ģ���\�б����������ģʽ���@������Ӌ��Ч���c�ܶȡ�
�Ȟ�ֵ��һ����ǣ������ס�X3���������е�Ӳ���≺����WDC��ԓ���g�܌����^ܛ���o�p���s�Ĵ�ģ�͙����M��Ӳ���≺���Ķ��~��@�üs15%�ĵ�Ч�����������@��һ험O����˼�ġ������U�ݡ����g��

����ϵ�y����������ؓ�d��ጷŶ˂�AI���΄՝���
���ˏ����Ӌ�������c�������ݣ������ס�X3��ϵ�y���������挍�F����Ҫ���g�w�S���伯�ɵ�AI����Ӳ������AIFF�c����Ӳ���{�����fͬ������������һ��Ч�Į���Ӌ��ܘ����܉�CPU�ķ��ص�AI�΄��{���н�ų����������Pؓ�d���������0.5%�ĘO��ˮƽ��ͬ�r���F�뼉�ij����{�����t��
�@��ϵ�y����������������ֱ�Ӄ������ڣ������d�����ס�X3�ĽK���O����Ҫ����̎���Z���R�e���h����֪�͈D��̎���ȶ��AI�΄Օr�������΄�֮�g�܉F���ʵ��YԴ�����c�o�p�ГQ���Ñ��ڌ��Hʹ���Ў����ܲ����κο��D�����t��ϵ�y푑�ʼ�K���ָ�Ч�������@�N���o�С��s����Ķ��΄�AI�w���ǡ����ס�X3��ϵ�y�ܘ��OӋ�ϵ�ͻ�����x��Ī��rֵ��Ҳ�˂����ܵ������ռ���ǰ�~�M��һ��
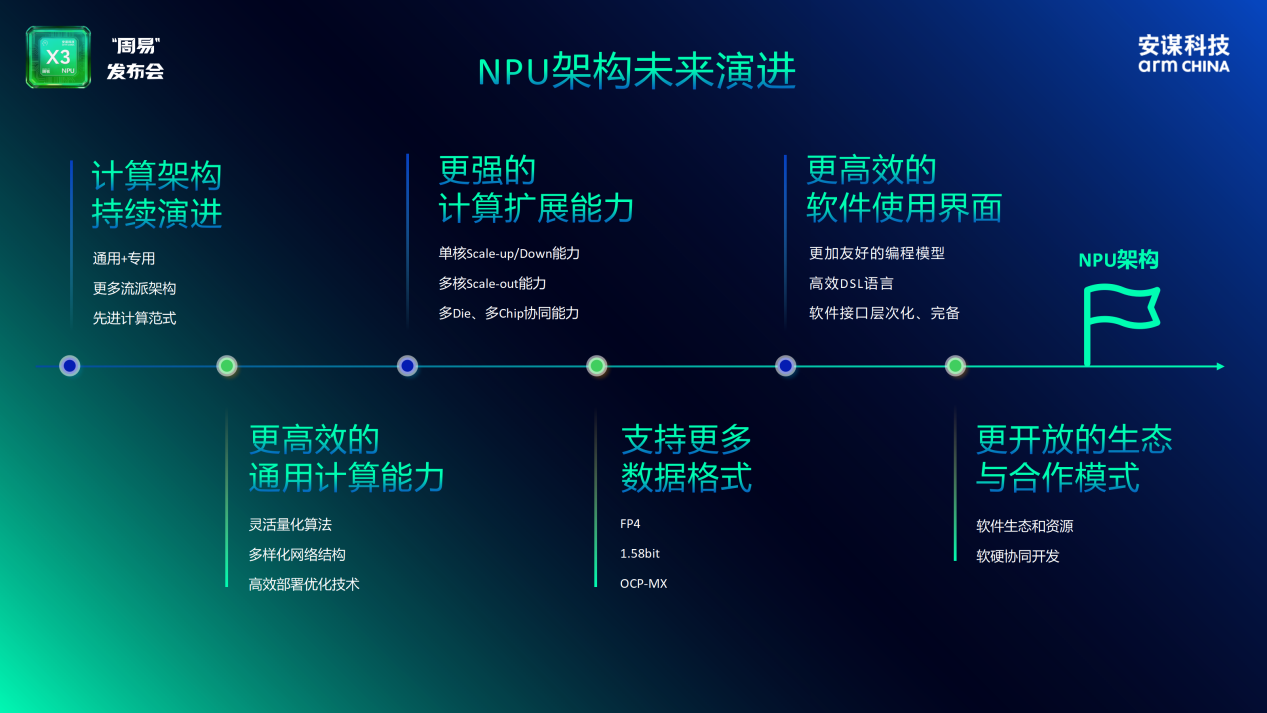
��������Ĵ��I���Ӷ˂�AIҎģ������
�{��������Ч�ȡ�Ӌ���ܶ��cͨ���Եȷ���ľC�σ��ݣ������ס�X3������һ��AI����оƬ�������ڞ���A�Oʩ��������܇���ƄӽK�ˡ��������W�@�Ĵ��P�I�I���ṩ���ɿ��ĺ���AI����֧�Ρ�
�ھ��w�����У������ס�X3�܉��Ч̎��ď��s���ƶ����������r��Ҫ��O�ߵ�߅�������΄ա����磬��������܇�I������ͬ�r������֧�ֶ�·����z���^�M�Эh����֪���{�T��B�O�أ����������W�ˣ����t�������z���^�߂�����ʵ������R�e�c�О���������������ܼҾ��O�䌍�F����Ȼ���Z�����������İl����������� �Dʮ�����_������Ҫͨ�^��ͻ���Ե�Ӳ���ܘ��OӋ�cܛ������朵���ȃ�����������˂�AI��Ӌ��Ч�ʡ����Ŀ��Ƽ��ɱ�Ч���ϵ�ȫ���ИI�˗U��

���鰲�\�Ƽ��đ��Ժ��ĮaƷ�������ס�NPU���аl�c֧��100%�����Ї������Fꠣ������ѳɹ���������aƷ���e�������ļ��g�c�Ј����ڮ�ǰ�Ї��ѳɞ�ȫ��˂�AI�����c��ؘ��^���ı����£������ס�X3���Ƴ�������Armȫ�����Bϵ�y������ں�����IP���o�Ɍ�����������ݱ��AI���Ä���ע��һ�ɏ��ŵġ�о�������� 


































