









�� 2024 ���𣬴�ģ���аl�����Ćμ����AӖ���D����|�������������ģ�Ͳ��HҪ“����”����Ҫ“����”���� OpenAI �� o1 �������һ������ģ�ͣ�ͨ�^�ಽ�����@�������e�`�ʣ�������“����r��”�ĵ�����2025 �����DeepSeek �Ć������@һڅ���Mһ���Ŵ�DeepSeek ͨ�^��헹����c�㷨����——���� MOE�������Ҳ��У����� pipeline ��ˮ�����w���Լ� MLA��Multi-head Latent Attention�����ȉ��s�Խ��� KVcache ������——��Ч�����˴�Ҏģ������ƿ�i���@������Ӗ���c�������ܣ�����ʹ�óɱ����Ķ��ɞ����m��ģ�͵ĵ��ʹ�����
�� RAG �ȼ��g���Ƅ��£����������L����ݔ�뷽�����M���c��ͬ�r�����μ��AӖ���ďS�̔������@�p�٣��ИI�������c������“��Ч���ͳɱ�����������”�۔n���l������̕r�g������ͳɱ��@�ø��ߵ��������棬�l�������������Ј���“������”���A�ø�����Ј��c�������g��AI ��δ�팢�������ӣ��������Ą�ؓ��ȡ�Q���l�ܰ����������O�²��ѳɱ�������͡������@һ�c�����ǰ���δ�������Ј���Ԓ�Z�ࡣ
AI��Ⱥ���팦�������A�Oʩ��Ҫ��
�ᵽ�����Ļ��A�Oʩ���Ͳ��ò���Prefill�cDeocde���x����ʽ���҂��ȁ��˽���ʲô��prefill��decode��
�� Prefill���A��䣩�A�Σ�̎���Ñ���ȫ��ݔ�룬�����P��Ϣ���� KV cache�������ɵ�һ�� token��ÿ�������΄��У�Prefill ֻ����һ�Ρ�
�� Decode����a���A�Σ����Իؚw��ʽ�����ɺ��m token���e������ݔ�������L�Ȟ� 1024���t Prefill �a���� 1 �� token��Decode �����ʣ��� 1023 �����ɲ�����
Prefill�A�ε�������Ӌ���ܼ���Compute bound���� ����Ҫ��vģ�����Ќ��M��ǰ��Ӌ�㣬������ꇳ˷�ʹ�����g���ȣ�FLOP/Byte���ܸߡ�GPU/���ٿ�������������ͨ�����_ 80%–90%���� HBM��Ƭ�ϸߎ����ȴ棩�L�������^�٣����������ʃH�邀λ���ٷֱȣ�����������ƿ�i����˿�ͨ�^�p�� HBM ���������������ø��ͳɱ��� HBM �����Ϳ��w�ɱ���
Semianalysis ��HBM�ijɱ���Ԕ���ķ��������D1��ʾ����NVL72��GB300�У�HBM�ɱ�ռ�ȸ��_61%����Ӌ���ܼ��͵�prefill�A�Σ�HBM�д����ĕr�g��̎�ڿ��e��B���@�nj����F��HBM���YԴ�O�����M��
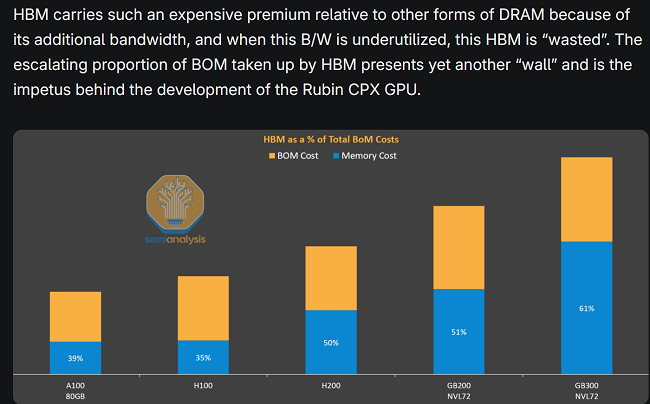
�D1 �� HBM�ɱ�ռ��
��Decode�A�ε��������L���ܼ���memory bound���ͣ�ÿ����һ�� token ����� HBM ���� KV��ͨ�����ʮ MB����оƬ̎���Ԫ��SM�������������ʿ��_ 70%–90%��Decode �A���l���M�� batch �M���c KVcache/�����xȡ������L�控��ֱ�ӛQ�������t�c���£��ɞ��P�I����ƿ�i��
��ˣ��ڌ��H���������� Prefill �� Decode �քe�ŵ���ͬ��͵�Ӳ�����c������“�������c”�c“�������c”�������@���������w���²��������t���������c��Compute optimized������ Prefill �ṩ�� FLOPS���^�� HBM Ҫ���Ӳ�����ã����ͳɱ����������c��Memory optimized������ Decode �ṩ������������ HBM�������L��ƿ�i�������� token���t�����¡� �D2��ܛ&�Aʢ�D��W�о��ɹ���ͨ�^PD���x�����F�������ܵĴ����������������240%�������ɱ������ϛ]��׃����

�D2 �� ܛ&�Aʢ�D��WPD���x�����о��Y��
Ӣ���_ Rubin CPX���� Prefill �����������ɱ�ӭ���¹��c
2025��9��9�գ���Ӣ���_ AI ���A�Oʩ����ϣ�Ӣ���_�Ƴ���һ��� Prefill �A���OӋ�� GPU——Rubin CPX��Ӣ���_����Ҏģ�c������Ӌ�㸱���� Ian Buck �ڰl�������M���˽�B���ٷ����퓣�https://www.nvidia.com/en-us/events/ai-infra-summit/����Rubin CPX ��������������L���Lݔ�����Ј�����Ӣ���_Ӌ���� 2026 ����������Ј����D3��Rubin CPX�cӢ���_�����������Č��ȣ�ᘌ� Prefill �A�ε����c��Ӌ���ܼ�����������ͣ���Rubin CPX �����ˎ���{����FP4 ��ֵ�����s 20P���s�� R200 �� 2/3 ���ң������F�� HBM ��Q����ͳɱ��� GDDR7���@��� 288GB �s�p�� 128GB��
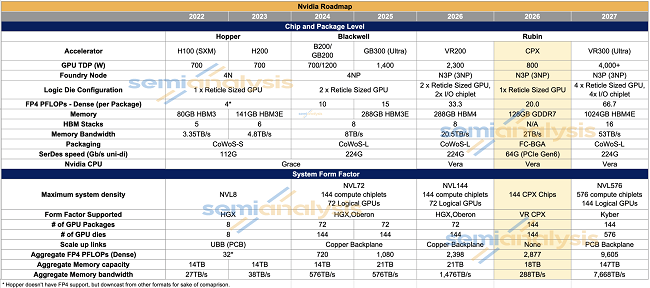
�D3��Ӣ���_��ͬϵ��GPUоƬ����
����׃��������@�����@�����Ͱl����׃�����҂���ǰ���¹��ᵽ��prefill�A����Ӌ���ܼ��͵ģ��L��ĴΔ����^�٣�ʹ�ð��F��HBM������YԴ���e�����M��ͨ�^���@���ГQ��r�������˵�GDDR�������L�控�����Mһ��������prefill�A�ε�Ӳ���ɱ��������ܻ��������Гpʧ�������@����Q�⣬CPX ߀ȡ���� NVLink �� NVSwitch �����ڴ�Ҏģ scale up �Ļ�Ӳ�����Ķ��Mһ�����s�˔Uչ�ɱ���
Rubin CPX �ṩ�ɷN�C��������ʽ���D4�����ο� 144 �� CPX���Լ� 144 �� CPX �c 72 �� R200 �M��ͬ�����@Щ�����У�CPX ����ه�� scale out���M��Uչ���W�j���B�Ӹ���оƬ�������ǂ��y�ĸ߳ɱ� scale up ����
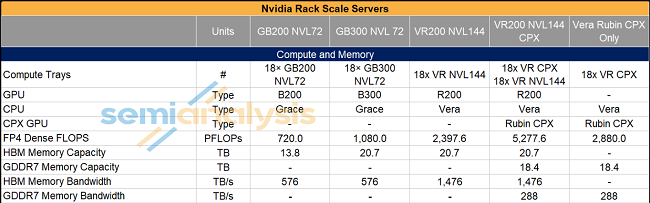
�D4��Ӣ���_�C����������B
�@��ζ����δ����������Ⱥ�ܘ��У��ͳɱ��� scale out �W�j��׃�����l��Ҫ��ͨ�^�M��Uչ���Y�Ϻ������{�Ȳ��ԣ����ڱ������µ�ͬ�r���Ϳ��w���гɱ���TCO����
�c Rubin CPX ͬ·���N�v950PR ����������ƽ�����
���A��ȫ�Ӵ�� 2025 �ϣ���ֱ܊�l���� Ascend 950PR/950DT �Լ� Ascend 960��970 ϵ�ЮaƷ�����У�Ascend 950PR �nj��� Prefill �A���OӋ�������������OӋ˼·�cӢ���_�� Rubin CPX �dz��ӽ�——ͨ�^��ᘌ��Ե��YԴ��ȁ����� Prefill ��Ӳ���ɱ������^��������V�������� 950DT��HBM ���� 4 TB/s����950PR ���@�控������ 1.6 TB/s��HBM ������ 144 GB �s�p�� 128 GB���Mһ��������Prefill�A�εijɱ���δ����ͨ�^scale-out�W�j�B��950PR�������ΑB���M��Prefill��Ⱥ���Mһ������scale-up���ɱ�������һ�����^�õ��x��
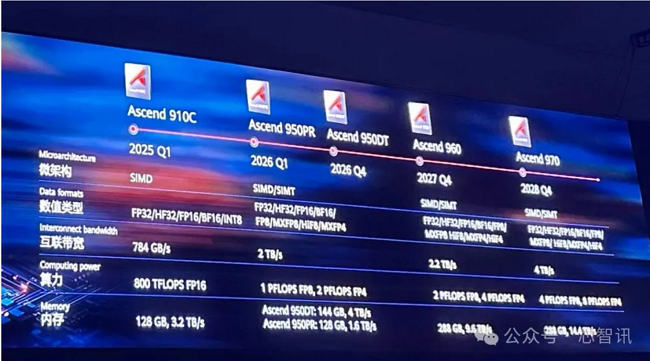
�D5���A��l���N�v950ϵ�ЮaƷ
����������δ��څ�ݣ��Ƅ�scale-out�W�j����
�N�v 950PR �cӢ���_ Rubin CPX ��˼·�ϸ߶�һ��——�� Prefill ����� ������֎������@���������Qȡ���͵�Ӳ���ɱ��c���ߵ��ԃr�ȡ��ɴ˿�Ҋ���������A���x�ò�ͬ�������ѳɞ����@څ��——���猢 CPX/950PR ���� Prefill�A�Σ��� R200/950DT �� Cloud Matrix 384 ���� Decode�A�Ρ�
���H�ϣ�ij�������W��˾�ѽ����F�������������� NVIDIA ������ Prefill �YԴ�ء��ó����c���ߎ������������� Decode �YԴ�ء�Prefill �A�Ϋ@�ø������ܶȲ����͔Uչ�ɱ���Decode �A�����������c�ṩ�����t�ʹ����M�㌦���r�ԣ�TPOT��Խ��Խ���̵�Ҫ���A���Ƶ��о�Փ��Ҳ�o�����Ʒ�������D6�����ÕN�v A2������ �� Prefill���N�vCloudMatrix384�����c�� Decode��������������Ќ��F�������ԃr�ȡ�

�D6���� xDeepServe: Model-as-a-Service on Huawei CloudMatrix384��
��ǰӢ���_����������Ȼ�I�ȣ������a XPU����N�v������o��Ħ�����̣����ڿ��������γɰٻ��R�ŵĸ�֡���ͬ�������������L���M�Ϯ������c�����ڳɱ��c�����gȡ�ø���ƽ�⡣���@�N�ܘ��£��D7����scale out �W�j��Ҫ���d���� KV cache ��ģ�ͅ������������@��scale-out�W�jҲ������µ�Ҫ��
��1����N�����c�ӿڼ��ݣ���Ҫ֧�� 200G/400G/800G ���룬����ͬ�r���d�惦������δ������߀������ XPU �W���ԫ@�ø������t�c���ߎ�����
��2�� �o�������߿ɿ���ͨ�ţ����������g��ͨ��ģʽ���s���W�j��횱��C�o����ͨ�ţ���Qؓ�d���⡢�����^��Ȇ��}������Ӱ��������t�c���¡�

�D7�������������ܘ�
���������˳����ˣ�scale-out�W�j�ʂ���ˆ 


































